Intel® Trust Domain Extension Guest Linux* Kernel Hardening Strategy¶
Contributors:
Elena Reshetova, Tamas Lengyel, Sebastian Osterlund, Steffen Schulz
Purpose and Scope¶
The main security goal of Intel® Trust Domain Extension (Intel® TDX) technology is to remove the need for a guest VM to trust the host and Virtual Machine Manager (VMM). However, it cannot by itself protect the guest VM from host/VMM attacks that leverage existing paravirt-based communication interfaces between the host/VMM and the guest, such as MMIO, Port IO, etc. To achieve protection against such attacks, the guest VM software stack needs to be hardened to securely handle an untrusted and potentially malicious input from a host/VMM via the above-mentioned interfaces. This hardening effort should be applied to a concrete set of software components that are used within the guest software stack (virtual BIOS, bootloader, Linux* kernel and userspace), which is specific to a concrete deployment scenario. To facilitate this process, we have developed a hardening methodology and tools that are explained below.
The hardening approach presented in this document is by no means an ultimate guarantee of 100% security against the above-mentioned attacks, but merely a methodology built to our best knowledge and resource limitations. In our environment, we have successfully applied it to the Linux TDX MVP software stack (https://github.com/intel/tdx-tools) to the trust domain (TD) guest Linux kernel and hardened many involved kernel subsystems. This guide is written with the Linux kernel in mind, but the outlined principles can be applied to any software component.
The overall threat model and security architecture for the TD guest kernel is described in the Intel® Trust Domain Extension Linux* Guest Kernel Security Specification and it is recommended to be read together with this document.
Hardening strategy overview¶
The overall hardening strategy shown in Figure 1 encompasses three activities that are executed in parallel: attack surface minimization, manual code audit, and code fuzzing. All of them are strongly linked and the results from each activity are contributed as inputs to the other activities. For example, the results of a manual code audit can be used to decide whenever a certain feature should be disabled (attack surface minimization) or should be a target for a detailed fuzzing campaign. Similarly, the fuzzing results might affect the decision to disable a certain functionality or indicate a place where a manual code audit is required but have been missed by a static code analyzer.
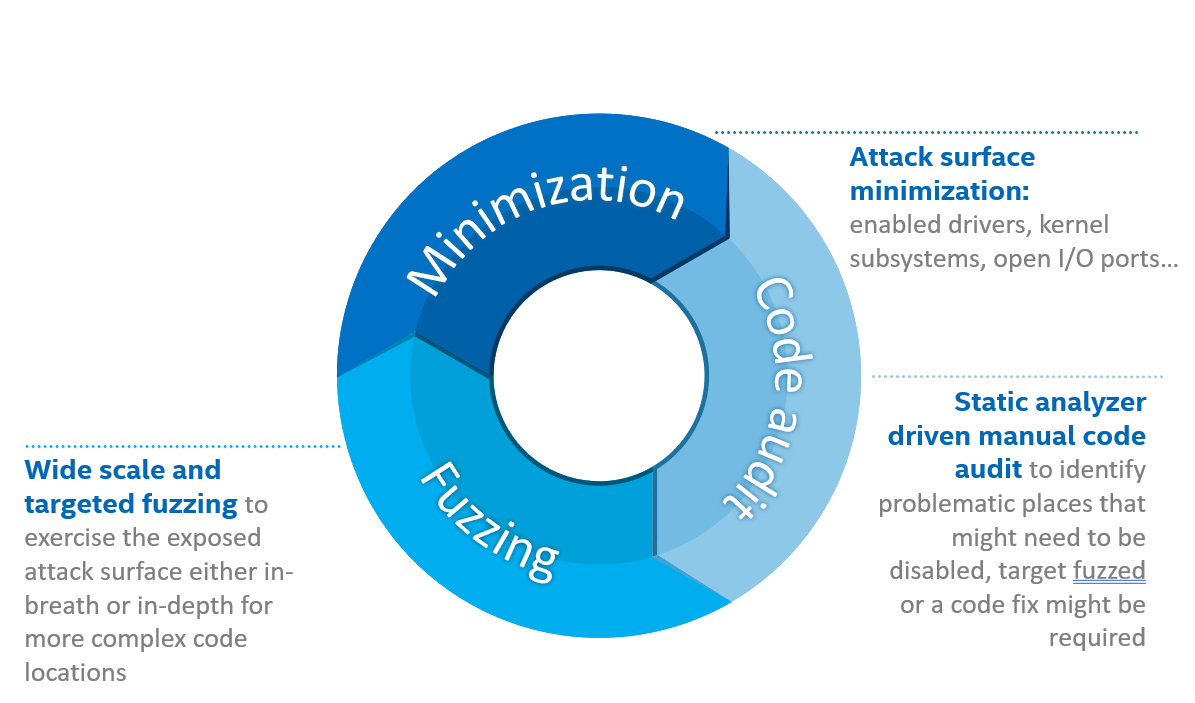
Figure 1. Linux Guest kernel hardening strategy.¶
The following section provides a detailed description of each of these activities. An overall crucial aspect to consider is the “definition of done”, i.e., the criteria for when a hardening effort can be finished and how the success of such effort is defined.
The ideal “definition of done” criteria can be outlined as follows:
The guest kernel functionality and the VMM/host exposed interfaces are limited to the minimum required for its successful operation, given a chosen deployment scenario. This implies that only a minimal set of required drivers, kernel subsystems, and individual functionality is enabled.
All code paths that are enabled within the guest kernel and can take an untrusted input from VMM/host must be manually audited from the potential consequences of consuming the malformed data. Whenever a manual code audit identifies an issue that is a security concern, it must be addressed either by a bug fix or by disabling the involved code path, if possible.
All code paths that are enabled within the guest kernel and can take an untrusted input from VMM/host must be fuzzed using an appropriate fuzzing technique. The fuzzing technique must provide the coverage information to identify that a fuzzer has reached the required code paths and exercised them sufficiently. Whenever the fuzzing activity identifies an issue that is a security concern, it must be addressed either by a bug fix or by disabling the involved code path.
The success of the overall hardening effort is significantly more difficult to measure. The total number of security concerns identified by the manual code audit or fuzzing activity is a natural quantifier, but it neither guarantees that the end goal of having a secure guest kernel has been successfully reached nor does it necessarily indicate that the chosen hardening approach is successful. The successful operation of the guest kernel within the Linux TD software stack and the absence of issues identified or reported during its deployment life cycle is a much stronger, albeit a post-factum indicator.
Attack surface minimization¶
The main objective for this task is to disable as much code as possible from the TD guest kernel to limit the number of interfaces exposed to the malicious host/VMM. This is achieved by either explicitly disabling certain unneeded features (for example early PCI code) , by a generic filtering approach, such as port IO filtering, driver filtering, etc or by restricting access to the MMIO and PCI config space regions
Implemented filtering mechanisms¶
All the implemented filtering mechanisms described below are runtime mechanisms that limit TD guest functionality based on a set of default allow lists defined in the kernel source code, but with a possibility to override these defaults via a command line option mechanism. The latter can be used for debugging purposes or for enabling a specific driver, ACPI table, or KVM CPUID functionality that is required for a particular deployment scenario.
Filter name |
Purpose and current state |
|---|---|
Driver filter |
Limits a set of drivers that are enabled in runtime for the TD guest kernel. By default, all PCI and ACPI bus drivers are blocked unless they are in the allow list. The current default allow list for the PCI bus is limited to the following virtio drivers: virtio_net, virtio_console, virtio_blk, and 9pnet_virtio. |
Port IO filter |
Limits a set of IO ports that can be used for communication between a TD guest kernel and the host/VMM. This feature is needed in addition to the above driver filtering mechanism, because should some drivers escape this mechanism, its port IO communication with the host/VMM will be limited to a small set of allowed ports. For example, some linux drivers might perform port IO reads in their initialization functions before doing the driver registration or some legacy drivers might not utilize the modern driver registration interface at all and therefore would be allowed by the above driver filter. In any case port IO filter makes sure that only a limited number of ports are allowed to be communicating with host/VMM. The port IO allow list can be found in IO ports. Note that in the decompressed mode, the port IO filter is not active and therefore it is only applicable for early port IO and normal port IO. |
ACPI table allow list |
TDX virtual firmware (TDVF, for details see https://www.intel.com/content/dam/develop/external/us/en/documents/tdx-virtual-firmware-design-guide-rev-1.pdf) measures a set of ACPI tables obtained from the host/VMM into TDX RTMR[ 0] measurement register. Thus, the set of tables passed by the host/VMM can be remotely attested and verified. However, it can be difficult for a remote verifier to understand the possible consequences from using a big set of various ACPI tables. Since most of the tables are not needed for a TDX guest, the implemented ACPI table allow list limits them to a small, predefined list with a possibility to pass additional tables via a command line option. The current allow list is limited to the following tables: XSDT, FACP, DSDT, FACS, APIC, and SVKL. Note that a presence of a minimal ACPI table configuration does not by itself guarantee the overall security hardening of ACPI subsystem in the TD guest kernel. The known limitations on ACPI hardening are described in BIOS-supplied ACPI tables and mappings. |
KVM CPUID allow list and KVM hypercalls |
KVM supports a set of hypercalls that a TD guest kernel can request a VMM to perform. On x86, this set is defined by a set of exposed CPUID bits. Some of the hypercalls can result in untrusted data being passed from a VMM KVM) to the guest kernel. To limit this attack vector, the implemented KVM CPUID allow list restricts the available KVM CPUID bits to a small predefined allow list. More information can be found in KVM Hypercalls and KVM CPUID. |
Explicitly disabled functionality¶
Most of the functionality described below takes an untrusted host input via MSR, port IO, MMIO, or pci config space reads through its codebase. This has been identified using the static code analyzer described in the next section. The decision to disable this functionality was made based on the amount of code that would have to be manually audited, complexity of the code involved, as well as the fact that this functionality is not needed for the TD guest kernel.
Feature type |
Description |
|---|---|
x86 features |
Some x86 feature bits are explicitly cleared out by the TD guest kernel during an initialization, such as X86_FEATURE_MCE, X86_FEATURE_MTRR, X86_FEATURE_TME, X86_FEATURE_APERFMPERF, X86_FEATURE_CQM_LLC. |
Various PCI functionality |
Some PCI related functionality that is not needed in the TD guest kernel is also explicitly disabled, such as early PCI, PCI quirks, and enhanced PCI parsing. |
Miscellaneous |
A malicious host/VMM can fake PCI ids or some CPUID leaves to enable functionality that is normally disabled for a TDX guest and therefore not hardened. To help prevent this from happening, support for XEN, HyperV, and ACRN hypervisors, as well as AMD northbridge support, is explicitly disabled in the TD guest kernel. |
Static Analyzer and Code Audit¶
Requirements and goals¶
The attack surface minimization activity outlined in the previous section helps to limit the amount of TD guest kernel code that actively interacts with the untrusted host/VMM. It is not possible to fully remove this interaction due to the functional requirements that the TD guest has; it needs to be able to perform network communication, it should be possible to interact with the TD guest via console, etc. Thus, we need to be able to manually audit all the TD guest kernel enabled code that consumes an untrusted input from the host/VMM to ensure it does not use this input in an unsecure way.
To perform a more focused manual code audit, the exact locations where the untrusted host input is consumed by the TD guest kernel needs to be identified automatically. We have defined the following requirements for this process:
Adjustability of custom kernel trees. The method must be easy to use on any custom kernel tree with any set of applied patches and specified kernel configuration.
Absence of code instrumentation. The expected number of locations where the TD guest can take an untrusted input from the host goes well beyond 1500 places even after the functionality minimization step. This makes it impossible to manually instrument these locations, as well as keep maintaining the instrumentation through the kernel version changes, custom patch sets, etc.
Open-source well established tool. The tool should be easily accessible for open source and for the kernel community to use and should be actively maintained and supported.
Check_host_input Smatch pattern¶
Based on the above requirements, a Smatch static code analyzer (http://smatch.sourceforge.net/) has been chosen since it provides an easy interface to write custom patterns to search for problematic locations in the kernel source tree. Smatch already has a big set of existing patterns that have been used to find many security issues with the current mainline kernel.
To identify the locations where a TD guest kernel can take an untrusted input from the host/VMM, a custom Smatch pattern check_host_input has been written. It operates based on a list of “host input functions”. The list contains known, low-level functions that perform MSR, port IO, and MMIO reads, such as native_read_msr, inb/w/l, readb/w/l, as well as higher-level wrappers specific to certain subsystems. For example, PCI config space uses many wrappers like pci_read_config, pci_bus/user_read_* through its code paths to read the information from the untrusted host/VMM. The output of the check_host_input pattern when run against the whole kernel tree is a list of findings with exact code locations and some additional information to assist the manual code audit process.
The current approach using the check_host_input Smatch pattern has several limitations. The main limitation is the importance of having a correct list of input functions since the pattern will not detect the invocations of functions not present in this list. Fortunately, the low-level functions for performing MSR, port IO, and MMIO read operations are well defined in the Linux kernel. The higher-level wrappers can be identified by using an iterative approach: run the check_host_input Smatch pattern to find all invocations of the low-level functions. By looking at these invocations, you can determine the next level wrappers, add them to the input function list, and re-run the Smatch pattern again. Another limitation of this approach is the inability to detect generic DMA-style memory accesses, since they typically do not use any specific functions or wrappers to receive the data from the host/VMM. An exception here is a virtIO ring subsystem that uses virtio16/32/64_to_cpu wrappers in most of the places to access memory locations residing in virtIO ring DMA pages. The invocation of these wrappers can be detected by the check_host_input Smatch pattern and the findings can be reported similarly as for other non-DMA accesses.
arch/x86/pci/irq.c:1201 pirq_enable_irq() warn:
{9123410094849481700}read from the host using function
'pci_read_config_byte' to an int type local variable 'pin', type is
uchar;
arch/x86/pci/irq.c:1216 pirq_enable_irq() error:
{11769853683657473858}Propagating an expression containing a tainted
value from the host 'pin - 1' into a function
'IO_APIC_get_PCI_irq_vector';
arch/x86/pci/irq.c:1228 pirq_enable_irq() error:
{15187152360757797804}Propagating a tainted value from the host 'pin'
into a function 'pci_swizzle_interrupt_pin';
arch/x86/pci/irq.c:1229 pirq_enable_irq() error:
{8593519367775469163}Propagating an expression containing a tainted
value from the host 'pin - 1' into a function
'IO_APIC_get_PCI_irq_vector';
arch/x86/pci/irq.c:1233 pirq_enable_irq() warn:
{3245640912980979571}Propagating an expression containing a tainted
value from the host '65 + pin - 1' into a function '_dev_warn';
arch/x86/pci/irq.c:1243 pirq_enable_irq() warn:
{11844818720957432302}Propagating an expression containing a tainted
value from the host '65 + pin - 1' into a function '_dev_info';
arch/x86/pci/irq.c:1262 pirq_enable_irq() warn:
{14811741117821484023}Propagating an expression containing a tainted
value from the host '65 + pin - 1' into a function '_dev_warn';
Figure 2. Sample output from the check_host_input Smatch pattern.
The sample output of the check_host_input Smatch pattern is shown on Figure 2. The function pirq_enable_irq performs a PCI config space read operation using a pci_read_config_byte input function (PCI config space specific higher-level wrapper) and stores the result in the local variable pin (type uchar). Next, this local variable is being supplied as an argument to the IO_APIC_get_PCI_irq_vector and pci_swizzle_interrupt_pin functions, as well as to several _dev_info/warn functions. The relevant code snippet with highlighted markings is shown in Figure 3.
The check_host_input Smatch pattern attempts to to provide a rough indication of severity for each finding via “warn” or “error” keywords highlighted in grey in Figure 2. Whenever a host input is being used as a condition for iteration, assigned to an external variable, returned by function, or being passed as an argument to a different generic function, the pattern reports such cases as “error” conditions. However, if the host input is being passed to a “safe output function” like various debug output, MSR, port IO, or MMIO write functions, the pattern reports such cases as “warn” conditions. Similarly, “warn” status is given to the cases when a function to obtain the host input is invoked, but its result is either not stored at all or used in a boolean expression to select one of the following code paths. The underlying idea behind the severity status is an attempt to assist the manual code audit process to indicate the code locations where the possibility of finding a security issue is higher. However, in its current form, it is strongly recommended to check both “warn” and “error” findings to make sure every single code path is secure.

Figure 3. Code snippet for the pirq_enable_irq function.
Performing a manual code audit¶
When a manual code audit activity is performed, the list of Smatch findings is first filtered using the process_smatch_output.py python script to discard the results for the areas that are disabled within the TD guest kernel. For example, most of the drivers/* and sound/* results are filtered out except for the drivers that are enabled in the TD guest kernel.
Next, the reduced list of Smatch pattern findings can be analyzed manually by looking at each reported code location and verifying that the consumed host input is used in a secure way.
Each finding is therefore manually classified into one of the following statuses:
Status |
Meaning |
|---|---|
excluded |
This code location is not reachable inside a TD guest due to it being non-Intel code or functionality that is disabled for the TD guest kernel. The reason these lines are not filtered from the Smatch report by the above process_smatch_output.py python script is additional checks that we do when executing the fuzzing activity described in the next section. We perform an additional verification that none of these excluded code locations can be reached by the fuzzer. |
unclassified |
This code location is reachable inside TDX guest (i.e. not excluded), but has not been manually audited yet. |
wrapper |
The function that consumed a host input is a higher-level wrapper. The function is being checked for processing the host input in a secure way, but additionally all its callers are also reported by the Smatch pattern and the code audit happens on each caller. |
trusted |
The consumed input comes from a trusted source for Intel TDX guest, i.e. it is provided by the TDX module or context-switched for every TDX guest (i.e. native). This is applicable for both MSRs and CPUIDs. More information can be found in MSRs and CPUID. |
safe |
The consumed host input looks to be used in a secure way |
concern |
The consumed host input is used in an unsecure way. There is an additional comment indicating the exact reason. All concern items must be addressed either by disabling the code that performs the host input processing or by writing a patch that fixes the problematic input processing. |
The main challenge in this process is a decision whenever a certain reported code location is considered “safe” or “concern”. The typical list of “concern” items can be classified into two categories:
Memory access issues. A host input is being used as an address, pointer, buffer index, loop iterator bound or anything else that might result in the host/VMM being able to have at least partial control over the memory access that a TD guest kernel performs.
Conceptual security issues. A host input is being used to affect the overall security of the TD guest or its features. An example is when an untrusted host input is used for operating TD guest clock or affecting KASLR randomization.
Applying code audit results to different kernel trees¶
The provided list at https://github.com/intel/ccc-linux-guest-hardening/tree/master/audit/sample_output/5.15-rc1 of Smatch findings for the version 5.15-rc1 kernel contains results of our manual code audit activity for this kernel (Please note that the provided list does not have ‘safe’ or ‘concern’ markings published) and can be used as a baseline for performing a manual audit on other kernel versions or on custom vendor kernels. Here is the suggested procedure:
Run the provided check_host_input Smatch pattern on a desired target kernel tree:
cd kernel_build_directory ~/smatch/smatch_scripts/test_kernel.shSmatch stores results in smatch_warns.txt in the root of the kernel build directory.
Process the smatch_warns.txt output using process_smatch_output.py python script. If any additional drivers or subsystems are enabled, the script can be easily modified not to filter these results from the output by adding them into tdx_allowed_drivers list.
python3 process_smatch_output.py smatch_warns.txt
The output file of this step, smatch_warns.txt_filtered, is a reduced list of check_host_input Smatch findings for a target kernel tree. This file should have all the relevant findings that should be manually audited.
Transfer existing manual code audit results from the provided source kernel tree results to the target kernel by running the transfer_results.py script.
python3 transfer_results.py existing_smatch_audit_results filtered_smatch_warns
The script produces three output files with the *_results_new, *_results_old and *_results_analyzed postfixes. The *_results_old file contains the manual code audit results that are matching between the existing_smatch_audit_results and the filtered_smatch_warns. These results do not have to be manually re-audited since the code in question has not changed.
The *_results_new file contains the results that were impossible to automatically transfer due to one of the following reasons:
The code location is new in the target kernel tree and has not been part of the previous analysis done for the source kernel tree.
The code location has existed before and has been manually audited, but there are some code changes between the target and source kernel trees that require manual re-auditing to confirm the status of the finding (i.e., “safe”, “concern”, etc.)
The reported code locations in the *_results_new file must be manually audited following the logic described in Performing a manual code audit. The *_results_analyzed file is a combination of the *_results_new and the *_results_old file with all the entries arranged in the order of static analysis scan.
The manual code audit results that were obtained by executing the transfer_results.py script are automatically transferred based on the unique identifiers for each finding. Examples of these findings are shown in orange in Figure 2. Identifiers from a source kernel tree finding and target tree finding must match for a finding to be automatically transferred. An identifier is a simple djb2 hash of an analyzed code expression together with a relative offset from the beginning of the function where this expression is located. It is possible to further improve the calculation of identifiers (and therefore improve the accuracy of automatic result transfer) to include the code around the expression in a way that it is done in various version control systems, but it has not been done yet.
TD Guest Fuzzing¶
Fuzzing is a well-established software validation technique that can be used to find problems in input handling of various software components. In our TD guest kernel hardening project, we used it to validate and cross check the results from the manual code audit activity.
The main goals for the fuzzing activity are:
Automatically exercise the robustness of the existing TD guest kernel code that was identified by the Smatch pattern as handling the input from the host/VMM.
Identify new TD guest kernel code locations that handle the input from the host/VMM and were missed by the Smatch pattern (for example some virtIO DMA accesses). When such locations are identified, the Smatch pattern can be further improved to catch these and similar places in other parts of the kernel code.
Automatically verify that the code that is expected to be disabled in the TD guest kernel (and thus not manually audited at all) is indeed not executed/not reachable in practice.
The primary ways of consuming untrusted host/VMM is by using either TDVMCALLs or DMA shared memory as used for example by the VirtIO layer. Additionally, the code paths that consume untrusted input may invoked automatically during boot, or require some additional stimulus to execute during runtime.
In the following we review options we considered for generating potential relevant userspace activity and fuzzing the various relevant input interfaces during boot as well as during runtime.
TDX emulation setup¶
Running a fully functional TDX guest requires CPU and HW support that is only available starting from Intel Sapphire Rapids (SPR) CPUs. On contrary, our TDX emulation setup allows testing SW running inside TDX guest VM early on and independent of the actual SPR HW availability. It can be run on any recent and commonly available Intel platforms without any special HW features. However it is important to note that this emulation setup is very limited in the amount of features it supports and absolutely unsecure: emulated TDX guest runs under full control of the host and VMM.
The main challenge for the setup is the emulation of the Intel TDX module. Intel TDX module is a special SW module that plays a role of a secure shim between the TDX host and TDX guest and provides an extensive API towards both VMM and TDX guest. However, since our goal is only fuzzing of the TDX guest kernel, we need a minimal emulation of the TDX Seam module that can support the basic set of calls that TDX guest does towards the TDX module, as well as wrapping such calls into existing kvm interfaces. For more details about the actual Intel TDX module and its functionality please see Intel TDX module architecture specification
Implementation details¶
The TDX emulation setup is implemented as a simple Linux kernel module with the code in arch/x86/kvm/vmx/seam.c. Whenever the core TDX code in KVM performs basic lifecycle operations on the TDX guest (initialization, startup, destruction, etc.) it would call the respected functions in the TDX emulation setup (seam_tdcreatevp, seam_tdinitvp/tdfreevp, seam_tdenter, etc.) instead of the actual TDX functions. The emulated seam module supports a minimal set of exit reasons from the TDX guest (including EXIT_REASON_TDCALL, EXIT_REASON_CPUID, EXIT_REASON_EPT_VIOLATION) and inserts a #VE exception into an emulated TDX guest when the guest performs operations on MSRs, CPUIDs, portIO and MMIO, as well as on guest’s EPT violations. Emulation performed by the TDX emulation setup is currently not exact but mainly focused on exercising and testing the relevant TDX support by the guest OS. Please refer to section 24 of Intel TDX module architecture specification for official guidance on TDX module interfaces. For example, for the emulation of the MSRs and CPUIDs virtualization the emulated seam
module does not adhere to the TDX module specification on MSR and CPUID accesses
outlined in section 19 of Intel TDX module architecture specification Instead it just inserts a #VE event on most of the MSRs operations and for the CPUID leaves greater than 0x1f or outside of 0x80000000u-0x80000008u range. The code in arch/x86/kvm/vmx/seam.c: seam_inject_ve() function can be checked for up-to-date details.
Fuzzing Kernel Boot¶
The majority of input points identified by Smatch analysis and manual audit are invoked as part of kernel boot. The invocation of these code paths is usually hard to achieve at runtime after the kernel has already booted due to absence of re-initialization paths for many of these kernel subsystems.
We have adopted the kAFL Fuzzer for effective feedback fuzzing of the Linux bootstrapping phase. Using a combination of fast VM snapshots and kernel hooks, kAFL allows flexible harnessing of the relevant kernel sub-systems, fast recovery from benign error conditions, and automated reporting of any desired errors and exceptions handlers.
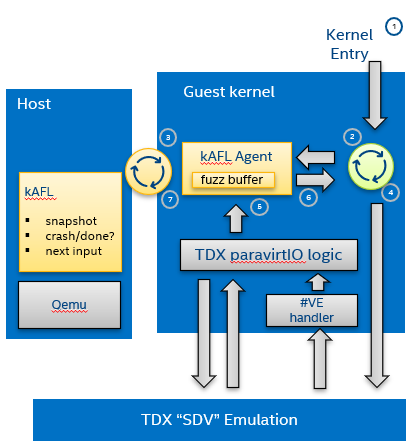
Figure 4. kAFL overview. 1) start of fuzzing (entry to kernel) 2) fuzzing harness 3) input fuzz buffer from host 4) MSR/PIO/MMIO causes a #VE 5) the agent injects a value obtained from 6) the input buffer 7) finally, reporting back the status to the host (crash/hang/ok)¶
Agent¶
While kAFL can work based on binary rewrite and traps, the more flexible approach is to modify the target’s source code. This implements an agent that directly hooks relevant subsystems and low-level input functions and feeds fuzzing input. At a high level, our agent implementation consists of three parts:
Core agent logic: This includes fuzzer initialization and helper functions for logging and debug. The fuzzer is initialized with tdg_fuzz_enable(), and accepts control input via tdg_fuzz_event() to start/stop/pause input injection or report an error event. https://github.com/IntelLabs/kafl.linux/blob/kafl/fuzz-5.15-3/arch/x86/kernel/kafl-agent.c
Input hooks: We leverage the tdx_fuzz hooks of in the guest kernel as defined by Simple Fuzzer Hooks as well as virtio16/32/64_to_cpu wrappers for VirtIO DMA input. When enabled, the fuzzing hooks are implemented to sequentially consume input from a payload buffer maintained by the agent. Fuzzing stops when the buffer is fully consumed or other exit conditions are met. https://github.com/IntelLabs/kafl.linux/commit/1e5206fbd6a3050c4b812a826de29982be7a5905
Exit and reporting hooks: We added tdx_fuzz_event() calls to common error handlers such as panic() and kasan_report(), but also halt_loop() macros etc. Moreover, the printk subsystem has been modified to log buffers directly via hypercalls. This allows report error conditions to be returned to the fuzzer and to collect any diagnostics before immediately restoring the initial snapshot for next execution.
Harnesses Definition¶
Our kAFL agent implements a number of harnesses covering key phases of boot:
Early boot process: EARLYBOOT, POST_TRAP, and START_KERNEL
Subsystem initialization: REST_INIT, DO_BASIC, DOINITCALLS, DOINITCALLS_PCI, DOINITCALLS_VIRTIO, DOINITCALLS_ACPI, and DOINITCALLS_LEVEL_X
Full boot (ends just before dropping to userspace): FULL_BOOT
Kretprobe-based single function harnesses: VIRTIO_CONSOLE_INIT and EARLY_PCI_SERIAL_INIT
The full list of boot harnesses with descriptions is available at https://github.com/intel/ccc-linux-guest-hardening/blob/master/docs/boot_harnesses.txt
These harnesses are enabled in the guest Linux kernel by setting up the kernel build configuration parameters in such a way that the desired harness is enabled. For example, set CONFIG_TDX_FUZZ_HARNESS_EARLYBOOT=y to enable the EARLYBOOT harness. When enabled, the kernel will execute a tdx_fuzz_enable() call at the beginning of the harness and a corresponding end call at the end of the harness. These calls cause kAFL to take a snapshot at the first fuzzing input consumed in the harness, and to reset the snapshot once the execution reaches the end of the harness. The fuzzer will continue resetting the snapshot in a loop – having it consume different fuzzing input on each reset – until the fuzzing campaign is terminated.
During the campaign, the fuzzer automatically logs error cases, such as crashes, sanitizer violations, or timeouts. Detailed (binary edge) traces and kernel logs can be extracted in post-processing runs (coverage gathering). To understand the effectiveness of a campaign, we map achieved code coverage to relevant input code paths identified by Static Analyzer and Code Audit (“Smatch matching”).
Example Workflow¶
Running a boot time fuzzing campaign using our kAFL-based setup typically consists of three stages, namely:
Run fuzzing campaign(s). Here we run the fuzzing campaign itself. The duration of the campaign typically depends on which harness is being used, how much parallelism can be used, etc. We have included a script (fuzz.sh) that sets up a campaign with some default settings. Make sure the guest kernel with the kAFL agent is checked out in ~/tdx/linux-guest. Select a harness that you want to use for fuzzing (in the next examples we will use the DOINITCALLS_LEVEL_4 harness). Using our fuzz.sh script, you can run a campaign in the following manner:
./fuzz.sh full ./linux-guest/
This starts a single fuzzing campaign, with the settings specified in fuzz.sh. You can get a more detailed view of the status of the campaign using the kafl_gui.py tool:
kafl_gui.py /dev/shm/$USER_tdflGather the line coverage. Once the campaign has run for long enough, we can extract the code line coverage from the campaign’s produced fuzzing corpus.
./fuzz.sh cov /dev/shm/$USER\_tdfl
This produces output files in the /dev/shm/$USER_tdfl/traces directory, containing information, such as the line coverage (for example, see the file traces/addr2line.lst).
Match coverage against Smatch report. Finally, to get an idea of what the campaign has covered, we provide some functionality to analyze the obtained line coverage against the Smatch report. Using the following command, you can generate a file (traces/smatch_match.lst) containing the lines from the Smatch report that the current fuzzing campaign has managed to reach. Run the Smatch analysis using:
./fuzz.sh smatch /dev/shm/$USER_tdflFor a more complete mapping of the PT trace to line coverage, we have included functionality to augment the line coverage with information obtained using Ghidra. For example, if you want to make sure that code lines in in-lined functions are also considered, run the previous command, but set the environmental variable USE_GHIDRA=1. E.g.:
USE_GHIDRA=1 ./fuzz.sh smatch /dev/shm/$USER_tdfl
We have included a script (run_experiments.py) that automatically runs these three steps for all the different relevant boot time harnesses.
Setup Instructions¶
The full setup instructions for our kAFL-based fuzzing setup can be found at https://github.com/intel/ccc-linux-guest-hardening
Fuzzing Kernel Runtime¶
Fuzzing the TD Guest Kernel at runtime is relevant for any code paths that are not exercised during boot or exercised during runtime with different context. Finding a way to reliably activate these code paths can be more difficult as an appropriate stimulus must be found. We present multiple options for finding a stimulus program and then fuzzing untrusted host/VMM inputs in context of that stimulus.
Fuzzing Stimulus¶
One challenge with TD guest kernel fuzzing is to create an appropriate stimulus for the fuzzing process, i.e. to find a way to reliably invoke the desired code paths in the TD guest kernel that handle an input from the host/VMM. Without such stimulus, it is hard to create good fuzzing coverage even for the code locations reported by the Smatch static analyzer. We considered the following options:
Write a set of dedicated tests that exercises the desired code paths. The obvious downside of this approach is that it is very labor-intensive and manual. Also, the Smatch static analyzer list of findings goes well beyond 1500 unique entries; this approach does not scale since some of the tests might have to be modified manually as the mainline Linux kernel keeps developing.
Use existing test suites for kernel subsystems. This approach works well for the cases when a certain type of operation is known to eventually trigger an input from the host/VMM. Examples include Linux Test Project (LTP), as well as networking and filesystem test suites (netperf, stress-ng, perf-fuzzer). The challenge here is to identify test programs that trigger all the desired code paths. Todo: put a coverage info + refer to section for usermode tracing/fuzzing for how to find/test own stimulus.
Automatically produced stimulus corpus. An alternative way of using existing test suites or creating new ones can be a method that would programmatically exercise the existing TD guest kernel runtime code paths and produce a set of programs that allow invocation of the paths that lead to obtaining an input from the host/VMM. Fortunately, the Linux kernel has a well-known tool for exercising the kernel in runtime – Syzkaller fuzzer. While being a fuzzing tool that was originally created to test the robustness of ring 3 to ring 0 interfaces, Syzkaller fuzzer can be used to automatically generate a set of stimulus programs once it is modified to understand whenever a code path that triggers an input from the host/VMM is invoked. However, the biggest problem with using Syzkaller in this way is to create a bias towards executing syscalls that would end up consuming the input from the host/VMM. This remains a direction for future research.
Simple Fuzzer Hooks¶
This simple fuzzer defines the basic fuzzer structure and the fuzzing injection input hooks that can be used by more advanced fuzzers (and in our case, used by the kAFL fuzzer) to supply the fuzzing input to the TD guest kernel. The fuzzing input is consumed using the tdx_fuzz() function that is called right after the input has been consumed from the host using the TDG.VP.VMCALL CPU interface.
The fuzzing input that is used by the basic fuzzer is a simple mutation using random values and shifts of the actual supplied input from the host/VMM. The algorithm to produce the fuzzing input can be found in __tdx_fuzz() from arch/x86/kernel/tdx-fuzz.c. The main limitation of this fuzzing approach is an absence of any feedback during the fuzzing process, as well as an inability to recover from kernel crashes or hangs.
The simple fuzzer exposes several statistics and input injection options via debugfs. TODO Refer documentation as part of Linux kernel sources.
KF/x DMA Fuzzing¶
Overview¶
DMA shared memory is designed to be accessible by the host hypervisor to facilitate fast I/O operations. DMA is setup using the Linux kernel’s DMA API and the allocated memory regions are then used by various drivers to facilitate I/O for disk, network, and console connections via the VirtIO protocol. The goal of using the KF/x fuzzer on these DMA memory regions is to identify issues in these drivers and the VirtIO protocol that may lead to security issues.
To fuzz the code that interacts with DMA memory, do the following:
Capture VM snapshot when DMA memory read access is performed
Transfer VM snapshot to KF/x fuzzing host
Identify stop-point in the snapshot
Fuzz target using KF/x
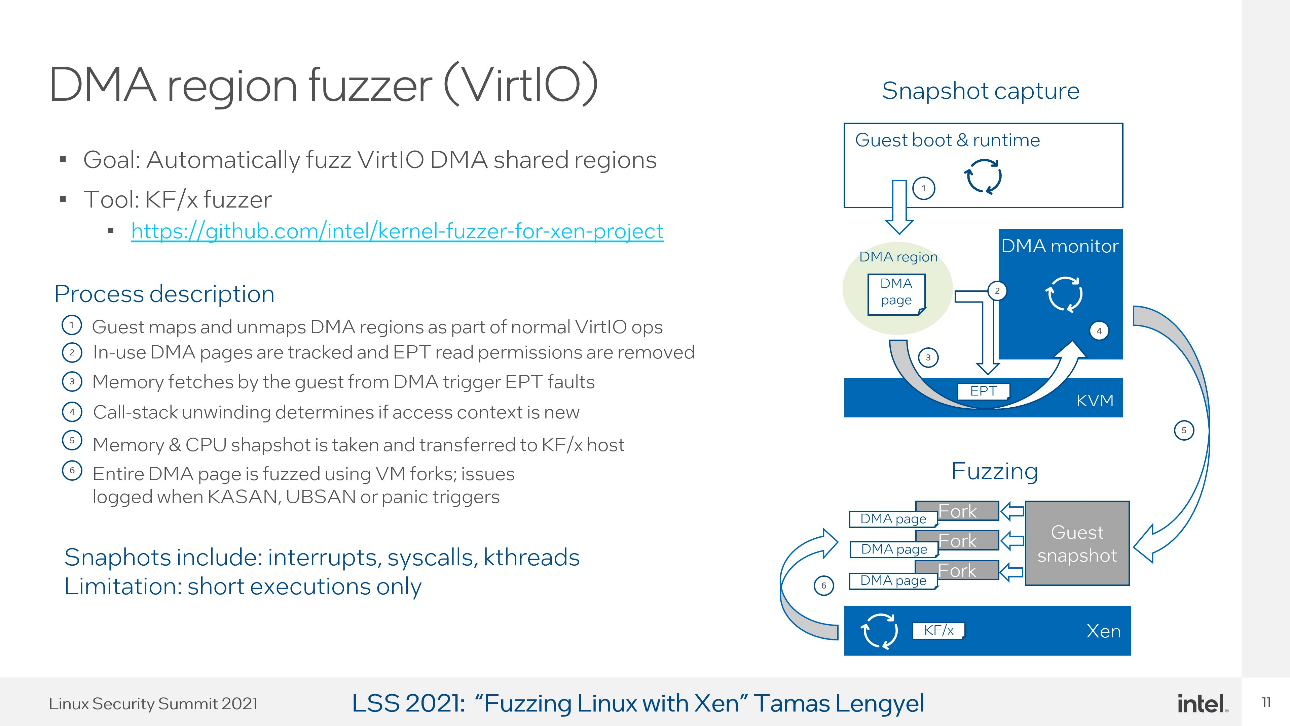
Figure 5. KF/x overview¶
Details¶
As the memory underpinning DMA is regular RAM, the guest-physical address is bound to run through the MMU’s Second Layer Address Translation via the Extended Page Tables (EPT). This allows us to restrict the EPT permissions and remove read-access rights from the VM. By removing EPT access rights of the memory regions designated to be DMA, the hypervisor gets a page-fault notification of all code-locations that interact with DMA memory. The Bitdefender KVM VMI patch-set is used for this introspection.
DMA regions are identified by hooking the Linux kernel’s DMA API via hypervisor-level breakpoint injection. By injecting a breakpoint into the DMA API responsible for mapping and unmapping memory, we can track which memory pages are designated to be DMA. The VM is booted with this monitoring enabled from the start and the EPT permissions are automatically restricted for all pages that are currently DMA mapped.
As DMA accesses are very frequent, the number of snapshots taken are reduced by observing the call-stack leading to the DMA access. For this, the kernel is compiled with stack frame pointers enabled. By hashing the four top-level functions on the call-stack, we identify whether a given DMA access is performed under a unique context or not (such as a particular system-call, kernel thread, etc.).
The faulting instruction is then emulated by the hypervisor to allow the DMA access to continue without the kernel getting stuck trying to access memory.
Snapshots are transferred to KF/x fuzzing hosts running on Xen. Snapshots are loaded into VM-shells by transplanting the snapshots’ memory and vCPU context.
The transplanted snapshot is executed up to a limited number of instructions (usually between 100k-250k) and logged to a file. Cross-reference the log with stacktrace to see how far back up the stack the execution reached. Place a breakpoint at that address.
KF/x is set up to fuzz the entire DMA page (4096 bytes) where the memory access was captured. The fuzzer is set to log any fuzzed input that leads to KASAN, UBSAN, or panic in the VM.
Setup instructions¶
Virtio snapshotting with KVM VMI · intel/kernel-fuzzer-for-xen-project Wiki (github.com)
kAFL Stimulus Fuzzing¶
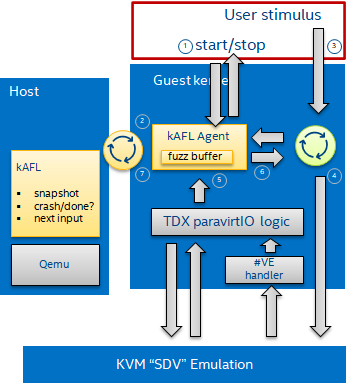
Figure 6. kAFL runtime fuzzing overview. 1) start of fuzzing 2) input fuzz buffer from host 3) stimulus is consumed from userspace 4) MSR/PIO/MMIO causes a #VE 5) the agent injects a value obtained from 6) the input buffer 7) finally, reporting back the status to the host (crash/ hang/ ok)¶
The kAFL agent described earlier can also be used to trace and fuzz custom stimulus programs from userspace. The kAFL setp for userspace fuzzing uses to following additional components:
kAFL agent exposes a userspace interface via debugfs. The interface offers similar controls to those used to implement boot-time harneses inside the kernel, i.e. start/stop as well as basic statistics.
The VM must be started with a valid rootfs, such as an initrd that contains the stimulus program. The kernel is configured with CONFIG_TDX_FUZZ_HARNESS_NONE; it boots normally and launches the designated ‘init’ process. Fuzzer configuration and control is done via debugfs.
To avoid managing a large range of filesystems, kAFL offers a ‘sharedir’ option that allows to download files into the guest at runtime. This way, the rootfs only contains a basic loader while actual execution is driven by scripts and programs on the Host. Communication is done using hypercalls and works independently of virtio or other guest drivers.
Harness Setup¶
As with the other runtime fuzzing setups, the kAFL setup requires an adequate “stimulus” to trigger kernel code paths that consume data from the untrusted host/VMM (either using TDG.VP.VMCALL-based interface or virtIO DMA shared memory). We setup kAFL to run any desired userspace binaries as stimulus input, using a flexible bash script to initialize snapshotting & stimulus execution from /sbin/init.
The usermode harness that is downloaded and launched by the loader can be any script or binary and may also act as an intermediate loader or even compiler of further input. The main difference from regular VM userspace is that the harness eventually enables the fuzzer, at which point the kAFL/Qemu frontend creates the initial VM snapshot and provides a first candidate payload to the kAFL agent. Once the snapshot loop has started, execution is traced for coverage feedback and the userspace is fully reset after timeout, crashes, or when the “done” event is signaled via debugfs.
Example harness using a stimulus.elf program:
#!/bin/bash KAFL_CTL=/sys/kernel/debug/kafl hget stimulus.elf # fetch test binary from host echo "[*] kAFL agent status:" grep . $KAFL_CTL/* # "start" signal initializes agent and triggers snapshot echo "start" > $KAFL_CTL/control # execute the stimulus, redirecting outputs to host hprintf log ./stimulus.elf 2>&1 |hcat # if we have not crashed, signal "success" and restore snapshot echo "done" > $KAFL_CTL/control
Detailed setup and scripts to generate small rootfs/initrd: https://github.com/intel/ccc-linux-guest-hardening/tree/master/bkc/kafl/userspace
More sophisticated “harness” for randomized stimulus execution: https://github.com/intel/ccc-linux-guest-hardening/tree/master/bkc/kafl/userspace/sharedir_template/init.sh